
文件系统有很多种,是广义的一个概念,例如 HDFS、GFS 这种分布式文件系统,以及 ZFS、ext4 这种只专注于宿主机上管理的文件系统。这里我们讨论的是兼容 posix 接口的文件系统。这样的文件系统可以直接使用 linux 的 mount umount 进行挂载,挂载点内是树状的结构,可以使用我们常见的 open,write 等接口进行交互,接口内部的实现则由文件系统自己定义,也就是说文件系统内部有可能是基于 block device、内存、web service 等等来实现的。
基础知识介绍
VFS
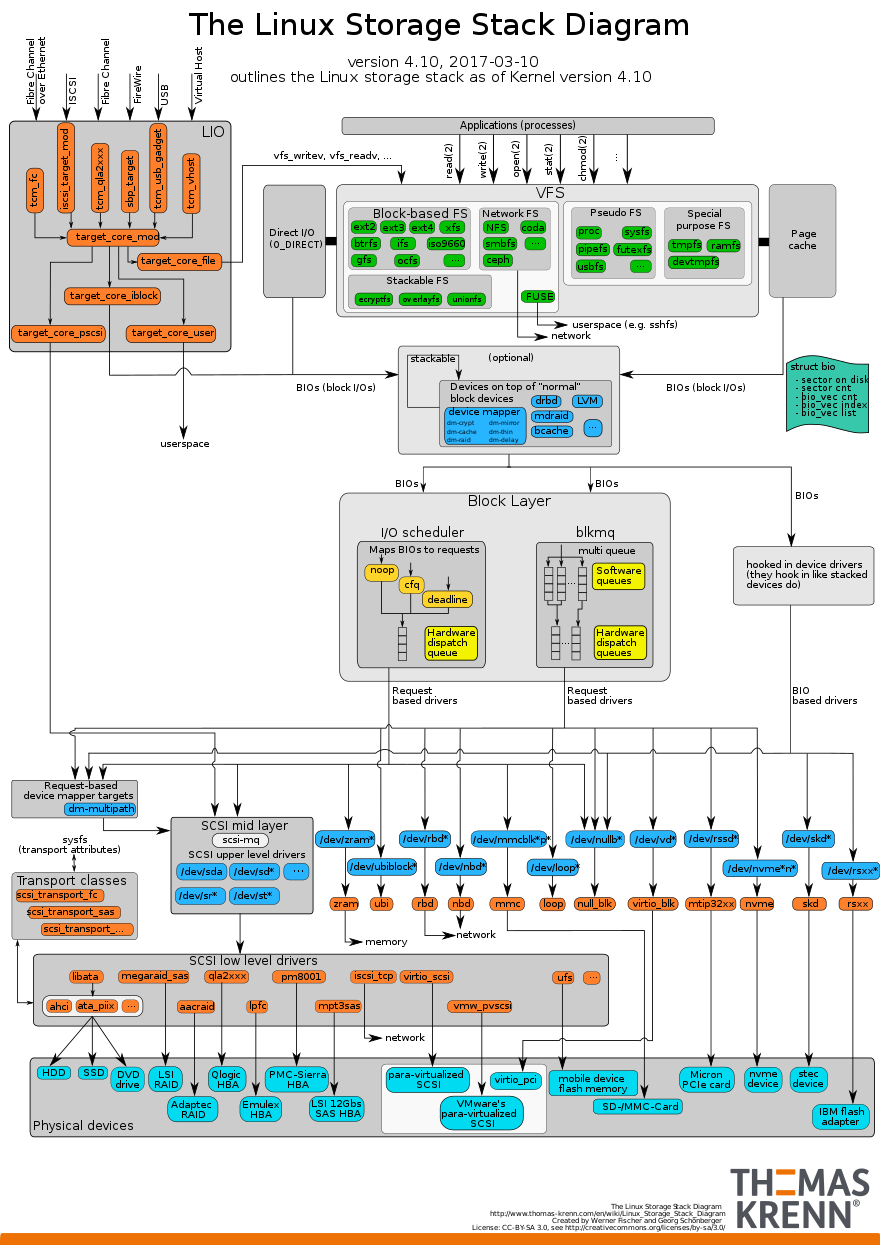 一图胜千言,从图中可以看到 VFS 作为衔接用户程序和块设备之间的一个系统,对用户屏蔽块设备、硬件细节,使用统一接口(open、write)等对下层文件系统进行访问。
一图胜千言,从图中可以看到 VFS 作为衔接用户程序和块设备之间的一个系统,对用户屏蔽块设备、硬件细节,使用统一接口(open、write)等对下层文件系统进行访问。
FUSE
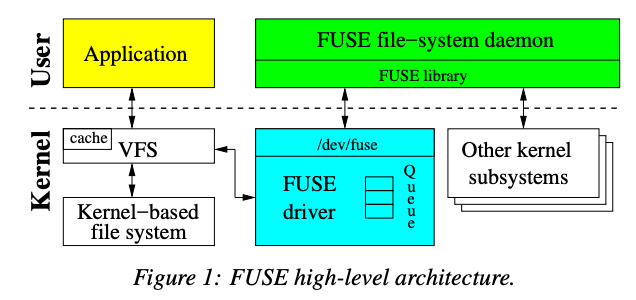 Filesystem in userspace,它能允许我们在用户空间实现文件系统,而且实现起来非常简单,一句话描述则是基于 /dev/fuse 通信协议的一套服务。 它定义了一组与 VFS 抽象的调用类似的消息。
用户程序与 VFS 通信,VFS 查询到访问的文件系统是由 FUSE 管理的,那么会向 /dev/fuse 发送指令,表明用户需要 readdir、read 或者 write 之类的操作,此时我们实现的 fuse 程序,可以从 /dev/fuse 里拿到消息,从而进行下一步处理即可。
Filesystem in userspace,它能允许我们在用户空间实现文件系统,而且实现起来非常简单,一句话描述则是基于 /dev/fuse 通信协议的一套服务。 它定义了一组与 VFS 抽象的调用类似的消息。
用户程序与 VFS 通信,VFS 查询到访问的文件系统是由 FUSE 管理的,那么会向 /dev/fuse 发送指令,表明用户需要 readdir、read 或者 write 之类的操作,此时我们实现的 fuse 程序,可以从 /dev/fuse 里拿到消息,从而进行下一步处理即可。
难点
事情总不是那么美好,要完整的实现 posix 接口,完完全全和本地文件系统一样的话,还是需要不少的代价的。
元数据
ls 是一个非常好用的指令,但是在 peerfs (千亿级文件数量)上的实现必然是阉割的,因为不可能将所有的文件(inode)在一台机器上创建完毕,这会耗费极大的内存,只能按需创建,有一些特定领域系统为了省略文件系统元数据大小,会将一些小文件合并在一个文件中,也会直接把 posix 的兼容给阉割掉,例如 HDFS,按照服务定义的交互的方式交互在全局上可以更优。
性能
用户态文件系统相比内核态文件系统,在目前还是有差距的。纵然用户态文件系统相对于内核态文件系统有很多优点:
- 开发简单,迭代快
- 实现 stackable 的文件系统
- Bug 不会 crash 整个系统 但是性能在某些场景下会差很多。从图中可以看到有三次数据流在用户态和内核态之间跳转,这里会有大量的内存拷贝,在现有 FUSE 的优化下,大文件读取与使用普通文件系统差别不大,但是有些场景下性能会降低 83%,CPU 的相对使用率也会提升 31%。更多验证细节可以看这里。 不过 FUSE 还在进行着优化。
相关优化
基本还是围绕两个点展开:
- 减少内存拷贝
- 减少磁盘 io
Splice
splice 是操作系统提供的功能,可以支持将一个文件拷贝到另外一个文件里,而不需要拷贝到用户态来。这在跨文件系统(设备)进行数据复制时带来的优势是巨大的。 VFS 是 stackable 的,也就是说一个文件系统 A 可以基于文件系统 B 实现,数据类似栈一样传递,这样的实现可以做一些去重或者压缩,类似文件系统界的网关。
Write back cache
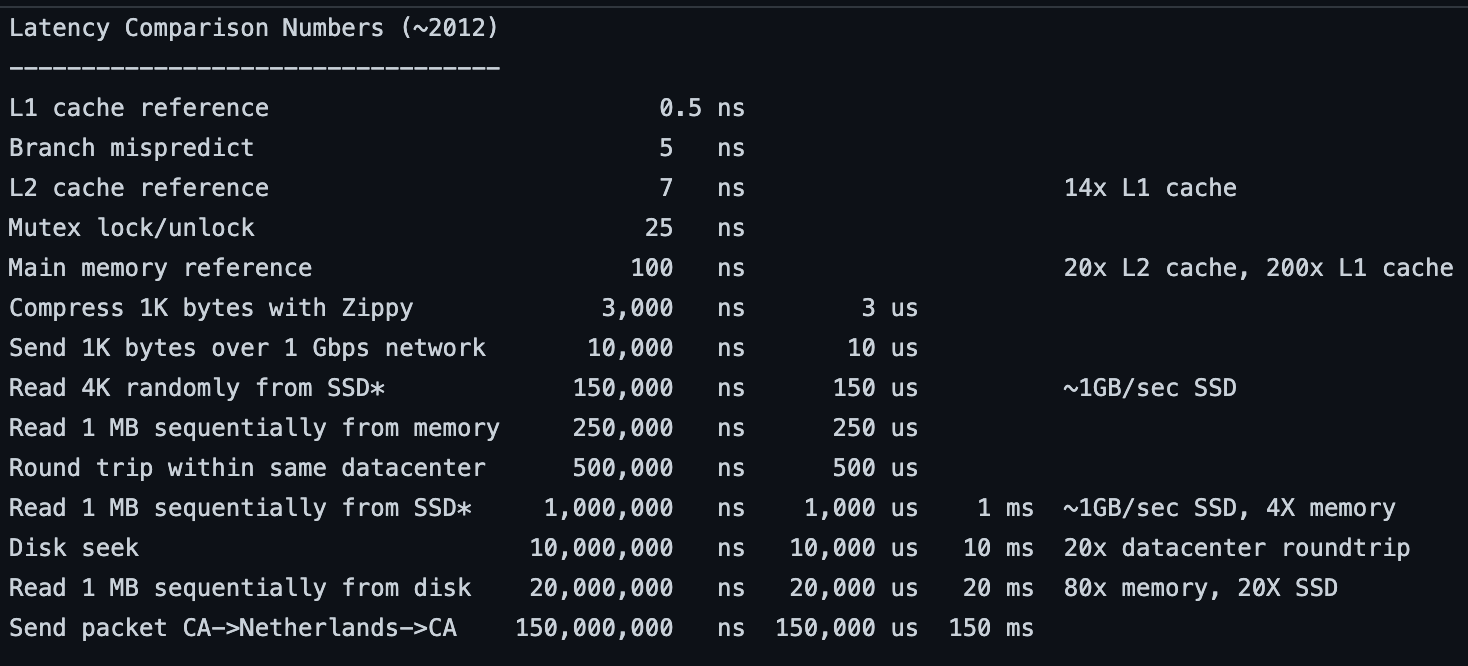
写 cache 的方式有两种,一种是 write back,一种是 write through。 Write through 和我们平时的使用方式比较类似,数据从分级存储,一层一层往后写,直到最后的存储存储完毕。例如数据服务接收到数据,在内存中缓存并写入磁盘保存,优点是数据一致性强,断电后数据也有保存。 Write back 则有一些不一样,数据先写第一层缓存,直到第一层缓存写满,内存需要换出时,根据策略(最少访问,最老创建等),将需要的数据写入后一级缓存,这带来的优势是吞吐量的提升。因为通常我们后一级的存储,响应时间是比前一层慢的,例如 L1 cache 相比 main memory,memory 相比 disk。
Reference
- https://uoryon.github.io/articles/2021/04/27/haystack-%E5%AD%A6%E4%B9%A0.html
- https://en.wikipedia.org/wiki/Virtual_file_system
- https://en.wikipedia.org/wiki/Filesystem_in_Userspace
- https://www.usenix.org/system/files/conference/fast17/fast17-vangoor.pdf