
最近在涉猎存储相关的一些知识,要补习的东西还是比较多,网络、存储、IO。其中之前没接触过的东西还蛮多,正好听分享的时候,有听到对象存储相关的东西,说是借鉴了一些 Haystack 的设计,那也顺便学习一下。
Haystack
Haystack 是 facebook 实现的基于图片的对象存储。主要是三个组件
- Haystack Directory
- Haystack Cache
- Haystack Store
在讲流程之前,需要额外提的一点是系统中有一个 Logical Volume 的概念,这个概念封装了 Physical Volume,这可以将多个 Physical Volume 映射到一个 Logical Volume 内,这个操作是为了做冗余,也就是 High Availablity(HA)。真实数据实际存在多个备份,防止坏盘,也可以提供读取负载均衡的功能。
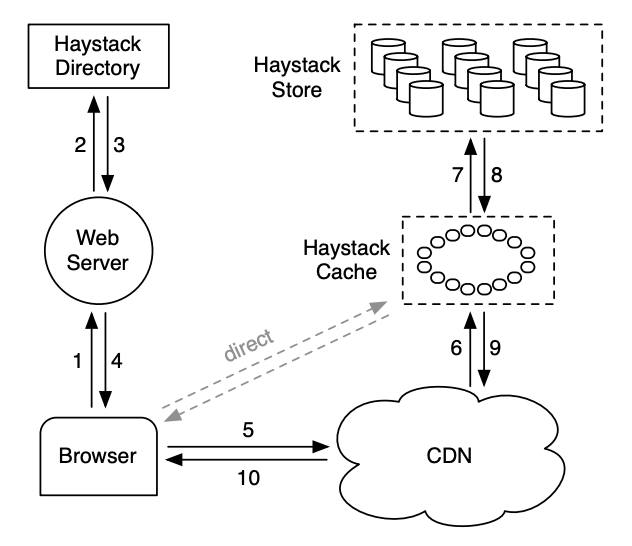
接下来就可以进入流程的环节了,用户通过 Haystack Directory 请求图片对象的访问 URL。Directory 会返回 CDN 地址,或者 Haystack Cache 的地址,让用户去访问。这里的 Cache 其实也是类似 CDN 的作用,为了区别外部 CDN,这样设计是为了减少自己对外部 CDN 的依赖,同时自己的 Cache 服务,能做更多针对性的优化。同时对于 CDN 来说,Haystack Cache 也像它的源站缓存。CDN miss 后,会向 Haystack Cache 调用,当 Haystack Cache 也 miss 时,数据会落到 Haystack Store 上,实际的物理存储介质里。
(上传的过程先略过)
Haystack Directory
它主要做四件事情:
- logical volume 到 physical volume 的映射
- 不同 physical volume 的 load balance
- 选择流量到 CDN 上还是 Cache 上
- 标记 volume 的 read-only 属性
这些都比较好理解。read only 功能是当卷满了或者需要运维的时候做的操作,使得 SRE 们能够维护一下集群。标记是以机器为粒度的。
Haystack Cache
缓存系统,相似于 CDN。它是特殊设计过的,它只缓存满足两个条件的文件:
- 直接来自用户的请求,而不是 CDN 的请求
- 来自于可写集群的图片
文章中提到有两个原因,促使这样的决定。对于第一点,在内部集群缓存 CDN 来的请求是低效的,CDN 自身就有一个比较大的池子,而一次回源后,CDN 就应当有 Cache 了,短期内不应该再次回源,那么对于 Cache 来说,缓存一次的话,后面不会有访问,那么就白白浪费了内存。 而第二点来说,这是基于冷热数据来分析的,用户通常会访问刚刚上传完的图片,这个也在时间点的最前面,很符合直觉。
Haystack Store
这一部分是主要和 disk 交互得比较多。最核心的设计是,获取文件名、offset、大小不需要任何磁盘操作。这类数据称为 filesystem metadata。这些 metadata 为了避免 disk 相关的操作,都是存在 main memory 中的。Haystack 在此之上还做了一些优化,可以估测出图片在数量上是非常大的,那么元数据/文件大小就会变得低,比较浪费 memory,存储效率低,很直接的优化就是将多个图片文件合并成一个大文件。(索引相关的也略过。)磁盘操作的话,顺序写这些都是基础操作了。 选择了 XFS 来作为文件系统,这个 FS 对预创建文件、碎片迁移效率很高,以及对元数据的内存使用很小。
重点总结
分布式系统必备的技能就不重复了。 看到的核心思想是尽可能的省略磁盘操作,这个操作会极大的影响延迟和吞吐量,这对对象存储系统来说是很重要的。 于是把很多数据放到了内存中,下一步,就是优化内存的使用。 Cache 的缓存策略也很有意思,算一种启发,这个之前工作有遇到类似的问题,但是没有这么系统的整理和认识。