
早在学校里就学习了数据库相关的东西,但是具体到细节的实现,了解得还是比较少,仅以这篇文章来回顾一下 InnoDB 中使用的一些锁,最后会和事务一块联系起来,做完整的一个介绍,彻底的理解 InnoDB 的锁与事务实现。
要实现大规模、负载高以及高可用的数据库应用,或者 mysql 调优,了解清楚 InnoDB 的锁机制和 InnoDB 的事务模型非常重要。
Shared and Exclusive Locks
共享(S)锁和排他(X)锁
- 共享锁,允许持有该锁的事务,读取这一行
- 排他锁,允许持有该锁的事务,删除或更新这一行
如果事务 T1 持有行 r 的共享锁,那么新事务 T2 申请这一行的 S 锁能立马得到,结果是 T1 和 T2 都持有这个 S 锁。而如果 T2 申请这一行的 X 锁,那么就不能立马得到它。 如果事务 T1 持有行 r 的 X 锁,事务 T2 拿这一行的任意锁,都不会立马得到响应,会被锁住,直到 T1 释放这个 X 锁。 这个和我们程序里并发控制的锁还是挺相似的,类似读写锁。
Intention Locks
为了满足 innodb 的表级锁与行级锁共存,那么实现了 Intention Locks。
Intention locks 是表级别的锁,表明之后这个事务会对这张表的某些行做操作,同时也有 IS 和 IX 两种。是上面基础锁的扩展。
例如当用户更新 user 表的行 r 时,会对 r 设置 X 锁,并对表设置 IX 锁。这样,另外一个事务锁定表的话,就会冲突,需要等待 IX 的释放。
具体锁的冲突如下 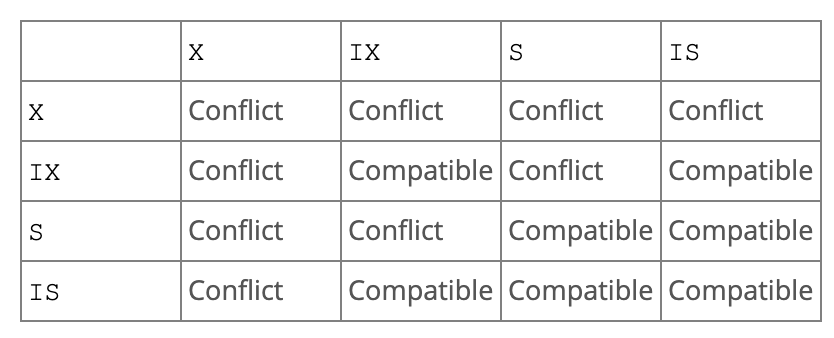
Record Locks
记录锁,锁在索引的记录上,例如 select c1 from t where c1 = 10 for update; 那么所有插入、更新、删除 c1 值为 10 的事务,都会被锁住。 如果加上范围的话,大胆拆测是在索引树上,对子节点进行锁定。后续查看锁定过程。
Gap Locks
gap lock 会锁住索引区间。 gap lock 是性能和并发间的取舍,有一些隔离级别需要,有一些不需要。 一个 gap 可能是单个索引值,多个索引值,甚至是空的。使用唯一索引去查找的话,不需要 gap lock。例如下面这一句。
SELECT * FROM child WHERE id = 100
如果 id 是 uk,那么就只会使用 record lock,而和 100 之前的数据是没有关系的。而 id 不是索引,或者也不是 uk 的话,这个语句会锁住之前的间隙。
间隙锁之间是会冲突的,”允许冲突的间隙锁的原因是,如果从索引中清除记录,则必须合并由不同事务保留在记录上的间隙锁。”对这一句体会还是比较浅显,了解得不多。 这是一个后面的todo
Next-Key Locks
next-key lock 是 index record 上 record lock 和 index record 之前的 gap lock 的结合。 当执行搜索或者扫描表索引的时候,innodb 使用 next-key lock,X 或者 S,这个会阻止别的事务影响这个键以及键之前的数据。 例如: 如果索引中有的值是 10,11,13 和 20。那么生成的锁区间是
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
innodb 默认使用可重复读的隔离级别,用来阻止幻读。
Insert Intention Locks
先跳过吧。
AUTO_INC locks
特殊的表锁,保证插入后获得的 key 是连续的。
Spatial Indexes
先跳过吧。
后记
为什么这里一点 sql 都没有,因为我意识到,如果要用 sql 解释清楚这些锁,应该需要对事务也做更好的理解,毕竟锁是一个工具,最终还是服务于事务,到时候会弄清楚。这一篇文章只是起点,可能只是翻译,也没有说得很明白,但是后面会结合更实际的例子,将这部分的知识给沉淀下来,争取介绍得更充分一些。
参考
innodb-locking 基本上都是这篇文章