
在做数据分析的时候,相对于传统关系型数据库,我们更倾向于计算列之间的关系。在使用传统关系型数据库时,基于此的设计,我们会扫描很多我们并不关心的列,这导致了查询效率的低下,大部分数据库 io 比较低效。因此目前出现了列式存储。Apache Parquet 是一个列式存储的文件格式。从这里入手,提升对列存的理解。当我还没看的时候,我还是很疑惑的,跟大家一样,向 hdfs 还是 lsmt 的设计,为了提升写入性能,都是使用 append 进行操作,而 append 如何将行式的数据转换成列式的数据呢?
Parquet
在深入 parquet 之前,我们需要先了解一下后面需要学习的术语。
术语
Block
Block(hdfs block):这是指 hdfs 的一个 block,parquet 运行在 hadoop 生态之中,文件的格式需要很好的与这些特征契合起来。 因为我之前也不知道这是什么,所以我们先来学习一下 Block 是啥。 Block 是 hdfs 中的最小的存储单元,使得其能将大文件切分为多个小文件,实现大文件的存储。并可以对多个小文件做合适的 replication,实现错误容忍(精髓)以及HA。 例如我们现在有一个文件一共是 518 MB,而设置的 hdfs block size 是 128 MB,那么它会由 5 个 block(128MB + 128MB + 128MB + 128MB + 6MB)来组成。所以我们处理数据的时候需要考虑同一行数据被写在两个不同的 block 上的情况,这里就不展开了(hdfs 细节还不是很清楚)。
File
一个 hdfs 文件,必定有 metadata。并不必须要数据。
Row Group
将我们的数据水平上的一个逻辑分区,按 mysql 来理解就是一些数据行,这些行组成一个 row group。这个 group 中包含数据集中每一列的 chunk(Column Chunk)。
Column Chunk
特定列的一大块数据。它存在于特定的一个 row group 中,并在物理上认为是连续的。
Page (column chunk 中)
column chunk 被划分为 pages。一个 page 认为是最小不可分割单元(就压缩和编码而言)。会有很多种 page type 在一个 column chunk 中交错存储。
一个文件会由一个或者多个 row group 组成,每个 row group 对其中一列只会存在一个 column chunk。column chunk 中含有多个 pages。
细节
基于以上的一些认知后,我们可以开始 Parquet 的细节描述了。
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"
上面这是从官网上摘抄下来的例子,一共有 M 个 row group,数据集中一共有 N 列。每个 row group 之后有一项 column 的 metadata。 在文件的末尾,有记录上 File Metadata,这个 file metada 中记录着每个 column metadata 的位置。通过这个信息,可以提取出关心的列。
这里附上两个图,都来自 Apache Parquet 官网的 document 里。就比较清晰数据结构了。
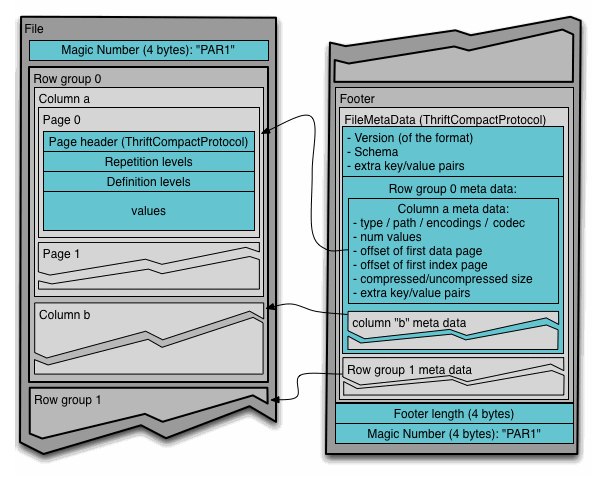
数据结构
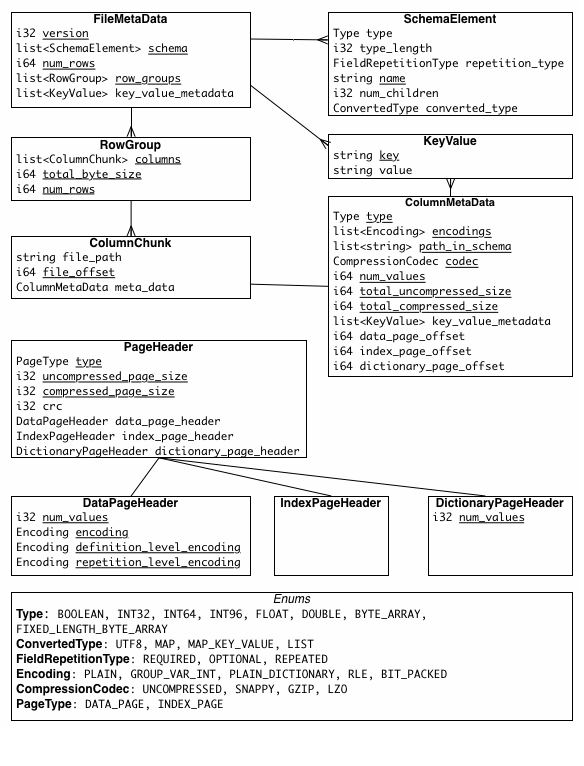
深入
以上的讲解都是概念性的,有点难理解,我一开始也没理解,到底什么是列存。 接下来我们从实际的例子中来解密 parquet。
parquet-cpp 原先是有自己的项目,后来迁移至 arrow 中了。我们用 arrow 的代码来学习过程。 代码使用的 commit 是 c29462c9
写入
// source code: https://github.com/apache/arrow/blob/master/cpp/examples/parquet/low-level-api
// 首先,书写 parquet 文件,需要先定义好对应的 parquet schema。这个 schema 用来描述我们的数据,数据有哪些列,每一列是什么样的类型。
std::shared_ptr<GroupNode> schema = SetupSchema();
// 设定写入的选项,压缩算法。
parquet::WriterProperties::Builder builder;
builder.compression(parquet::Compression::SNAPPY);
std::shared_ptr<parquet::WriterProperties> props = builder.build();
// 用定义好的 schema 和属性,创建写文件的对象实例
std::shared_ptr<parquet::ParquetFileWriter> file_writer =
parquet::ParquetFileWriter::Open(out_file, schema, props);
// 对这个文件新增 row group,注意是 buffered 的,因为 row group 的 size,可以由我们指定,而这个参数之后会影响到读取的效率。在后文有一些讨论,现在就不深入了。
parquet::RowGroupWriter* rg_writer = file_writer->AppendBufferedRowGroup();
// 后续针对每一行数据,进行对应 column 的写入。这个由于代码封装好了,使用起来也比较方便,就不细说了。想看具体如何使用的,可以去看看 c++ 的代码。
读取
文件结构的解析,我们在读取这一部分来阐述。而其中又以读 metadata 更为重要,那么解析一下读 metadata 的过程。
// parquet/file_reader.cc:158
void ParseMetaData() {
int64_t file_size = -1;
PARQUET_THROW_NOT_OK(source_->GetSize(&file_size));
if (file_size == 0) {
throw ParquetException("Invalid Parquet file size is 0 bytes");
} else if (file_size < kFooterSize) {
std::stringstream ss;
ss << "Invalid Parquet file size is " << file_size
<< " bytes, smaller than standard file footer (" << kFooterSize << " bytes)";
throw ParquetException(ss.str());
}
std::shared_ptr<Buffer> footer_buffer;
int64_t footer_read_size = std::min(file_size, kDefaultFooterReadSize);
PARQUET_THROW_NOT_OK(
source_->ReadAt(file_size - footer_read_size, footer_read_size, &footer_buffer));
// Check if all bytes are read. Check if last 4 bytes read have the magic bits
if (footer_buffer->size() != footer_read_size ||
memcmp(footer_buffer->data() + footer_read_size - 4, kParquetMagic, 4) != 0) {
throw ParquetException("Invalid parquet file. Corrupt footer.");
}
uint32_t metadata_len = *reinterpret_cast<const uint32_t*>(
reinterpret_cast<const uint8_t*>(footer_buffer->data()) + footer_read_size -
kFooterSize);
int64_t metadata_start = file_size - kFooterSize - metadata_len;
if (kFooterSize + metadata_len > file_size) {
throw ParquetException(
"Invalid parquet file. File is less than "
"file metadata size.");
}
std::shared_ptr<Buffer> metadata_buffer;
// Check if the footer_buffer contains the entire metadata
if (footer_read_size >= (metadata_len + kFooterSize)) {
metadata_buffer = SliceBuffer(
footer_buffer, footer_read_size - metadata_len - kFooterSize, metadata_len);
} else {
PARQUET_THROW_NOT_OK(
source_->ReadAt(metadata_start, metadata_len, &metadata_buffer));
if (metadata_buffer->size() != metadata_len) {
throw ParquetException("Invalid parquet file. Could not read metadata bytes.");
}
}
file_metadata_ = FileMetaData::Make(metadata_buffer->data(), &metadata_len);
}
就是我们的主体了,从这里开始进行 metadata 的分析。跟上文中的例子一样,首先读文件末尾 4-byte 的 magic number,如果不是 “PAR1” 的话,会直接抛出错误,认为文件损坏了。再继续读出 metadata 的size,通过 size 解析出 metadata 的内容,有了这些 raw data,我们便可以将其序列化成 Metadata 了。
// Metadata
/**
* Description for file metadata
*/
struct FileMetaData {
/** Version of this file **/
1: required i32 version
/** Parquet schema for this file. This schema contains metadata for all the columns.
* The schema is represented as a tree with a single root. The nodes of the tree
* are flattened to a list by doing a depth-first traversal.
* The column metadata contains the path in the schema for that column which can be
* used to map columns to nodes in the schema.
* The first element is the root **/
2: required list<SchemaElement> schema;
/** Number of rows in this file **/
3: required i64 num_rows
/** Row groups in this file **/
4: required list<RowGroup> row_groups
/** Optional key/value metadata **/
5: optional list<KeyValue> key_value_metadata
/** String for application that wrote this file. This should be in the format
* <Application> version <App Version> (build <App Build Hash>).
* e.g. impala version 1.0 (build 6cf94d29b2b7115df4de2c06e2ab4326d721eb55)
**/
6: optional string created_by
/**
* Sort order used for the min_value and max_value fields of each column in
* this file. Each sort order corresponds to one column, determined by its
* position in the list, matching the position of the column in the schema.
*
* Without column_orders, the meaning of the min_value and max_value fields is
* undefined. To ensure well-defined behaviour, if min_value and max_value are
* written to a Parquet file, column_orders must be written as well.
*
* The obsolete min and max fields are always sorted by signed comparison
* regardless of column_orders.
*/
7: optional list<ColumnOrder> column_orders;
/**
* Encryption algorithm. This field is set only in encrypted files
* with plaintext footer. Files with encrypted footer store algorithm id
* in FileCryptoMetaData structure.
*/
8: optional EncryptionAlgorithm encryption_algorithm
/**
* Retrieval metadata of key used for signing the footer.
* Used only in encrypted files with plaintext footer.
*/
9: optional binary footer_signing_key_metadata
}
后续可以继续深入去看了,其实就是上面 FileLayout.gif 那幅图。
除了使用源代码来学习,我们还可以使用官方提供的工具 parquet-tools 来分析 parquet 文件。
parquet-tool 有如下命令,命令的作用也很直白,就不展开介绍了。
cat
head
meta
schema
dump
merge
rowcount
size
column-index
下下来,本地使用一下即可。可以看到很多有用的信息,包括压缩率,Schema 等信息。 这里列部分上面我们写入的文件的 meta 信息,作为参考。
file: file:/xxx/arrow/cpp/examples/parquet/low-level-api/parquet_cpp_example2.parquet
creator: parquet-cpp version 1.5.1-SNAPSHOT
file schema: schema
--------------------------------------------------------------------------------
boolean_field: REQUIRED BOOLEAN R:0 D:0
int32_field: REQUIRED INT32 L:TIME(MILLIS,true) R:0 D:0
int64_field: REPEATED INT64 R:1 D:1
int96_field: REQUIRED INT96 R:0 D:0
float_field: REQUIRED FLOAT R:0 D:0
double_field: REQUIRED DOUBLE R:0 D:0
ba_field: OPTIONAL BINARY R:0 D:1
flba_field: REQUIRED FIXED_LEN_BYTE_ARRAY R:0 D:0
row group 1: RC:427502 TS:15645725 OFFSET:4
--------------------------------------------------------------------------------
boolean_field: BOOLEAN SNAPPY DO:4 FPO:4 SZ:2550/53476/20.97 VC:427502 ENC:RLE,PLAIN ST:[min: false, max: true, num_nulls: 0]
int32_field: INT32 SNAPPY DO:2615 FPO:1051257 SZ:2300579/2300478/1.00 VC:427502 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 00:00:00.000+0000, max: 00:07:07.501+0000, num_nulls: 0]
int64_field: INT64 SNAPPY DO:2303276 FPO:2827873 SZ:3706509/7227980/1.95 VC:855004 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0, max: 855003, num_nulls: 0]
int96_field: INT96 SNAPPY DO:6009885 FPO:6621698 SZ:3179187/5316039/1.67 VC:427502 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[no stats for this column]
float_field: FLOAT SNAPPY DO:9189128 FPO:10237777 SZ:2300592/2300478/1.00 VC:427502 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: -0.0, max: 470251.12, num_nulls: 0]
double_field: DOUBLE SNAPPY DO:11489804 FPO:12529844 SZ:3690680/3699099/1.00 VC:427502 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: -0.0, max: 475001.1063611, num_nulls: 0]
ba_field: BINARY SNAPPY DO:15180585 FPO:15244729 SZ:441270/608056/1.38 VC:427502 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0x70617271756574003030, max: 0x70617271756574FF3938, num_nulls: 213751]
flba_field: FIXED_LEN_BYTE_ARRAY SNAPPY DO:15621935 FPO:15622985 SZ:24358/430982/17.69 VC:427502 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0x00000000000000000000, max: 0xFFFFFFFFFFFFFFFFFFFF, num_nulls: 0]
row group 2: RC:427314 TS:15648394 OFFSET:15646373
--------------------------------------------------------------------------------
boolean_field: BOOLEAN SNAPPY DO:15646373 FPO:15646373 SZ:2550/53453/20.96 VC:427314 ENC:RLE,PLAIN ST:[min: false, max: true, num_nulls: 0]
int32_field: INT32 SNAPPY DO:15648992 FPO:16697641 SZ:2299840/2299726/1.00 VC:427314 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 00:07:07.502+0000, max: 00:14:14.815+0000, num_nulls: 0]
int64_field: INT64 SNAPPY DO:17948916 FPO:18473500 SZ:3705028/7224924/1.95 VC:854628 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 855004, max: 1709631, num_nulls: 0]
int96_field: INT96 SNAPPY DO:21654044 FPO:22265872 SZ:3177890/5313783/1.67 VC:427314 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[no stats for this column]
float_field: FLOAT SNAPPY DO:24831990 FPO:25880639 SZ:2299840/2299726/1.00 VC:427314 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 470252.22, max: 940296.5, num_nulls: 0]
double_field: DOUBLE SNAPPY DO:27131914 FPO:28180563 SZ:3697785/3697596/1.00 VC:427314 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 475002.2174722, max: 949794.4349465, num_nulls: 0]
ba_field: BINARY SNAPPY DO:30829800 FPO:30893940 SZ:441108/607877/1.38 VC:427314 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0x70617271756574003030, max: 0x70617271756574FF3938, num_nulls: 213657]
flba_field: FIXED_LEN_BYTE_ARRAY SNAPPY DO:31270988 FPO:31272038 SZ:24353/430797/17.69 VC:427314 ENC:RLE,PLAIN_DICTIONARY,PLAIN ST:[min: 0x00000000000000000000, max: 0xFFFFFFFFFFFFFFFFFFFF, num_nulls: 0]
row group 3: RC:427302 TS:15648549 OFFSET:31295421
row group size 的选择
row group size,这个指标会影响到我们的读取。因为 parquet 是 hadoop 生态下的产物,那么各项配置与 hadoop 契合起来,会有更大的威力。有如上文提到的 block,将每个 row group 的大小,设置为 block 的大小,则可以很好的提升 MR 程序的效率。至于 hdfs block 大小的调优,笔者刚接触这一块领域的知识,还没有详细的结论和见解,后续会有文章详细的阐述。
结论
那么这下我们就搞清楚了,parquet 将很多行数据划分进不同的 row group 中去,在 row group 里,把每一列数据进行顺序编码,是连续的,这样分析这里列的时候就是顺序的了,可以极大的利用好系统 io,提升读取性能。