
最近在做数据相关的事情。把我们线上的一个指标拉了下来。因为我们用到的都是第三方的服务,数据都维护在第三方。一个一个三方去看,还是比较麻烦的,也不好进行比对所以我们就全拉了回来,方便一起统计观看,同时也可以对这些数据利用起来,包括调度。
对这些数据的利用,最基本的是监控,其次需要针对这些数据做预测,其中一个点是需要做成本管理,预估之类的工作,第二点是要做异常检测。
异常检测也算是在探索之中吧,博主之前完全没有搞过,好多统计学的知识学校里也没有 学得很好。之后会有陆陆续续的文章,权当学习记录。
互联网的数据,特别是业务数据,特征性还是非常明显的。例如一个社交应用的访问量,一天之中,从早上起床开始,慢慢变多,直到中午的时候,迎来一个午高峰,随后到下午的时候,数据又渐渐的下降,晚饭后慢慢爬升至晚高峰,等到开始睡觉了,又慢慢降低下来。这是一天之内的变化。一周的变化也很明显,周末比工作日高。可以看到,我们的数据的季节性非常明显。调研到,现在有针对时序数据分解的方法Decomposition_of_time_series,于是采用了这种方式针对我们的数据进行了处理及预测,搭配 arima 数据的预测以及报警。
我们使用 python 来操作,还是比较轻松的。
1. 准备数据
我们的数据,现在全部收集在 InfluxDB 里面。找出来画个图:
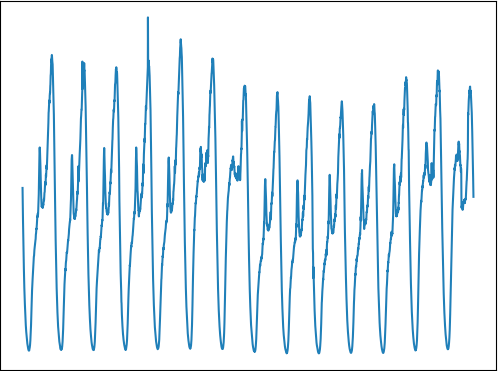 我们之后就基于这个数据来操作,做数据预测,以及异常检测。
我们之后就基于这个数据来操作,做数据预测,以及异常检测。
2. 将数据进行 stl 分解
stl 会将我们的数据分为趋势分量,季节分量和余量。
import pandas
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
decomposition = seasonal_decompose(pandas.Series([x[1] for x in data]),
freq=288, two_sided=False) # 数据粒度是 5 分钟,一天的数据是 288 个点
decomposition.plot()
plt.show()
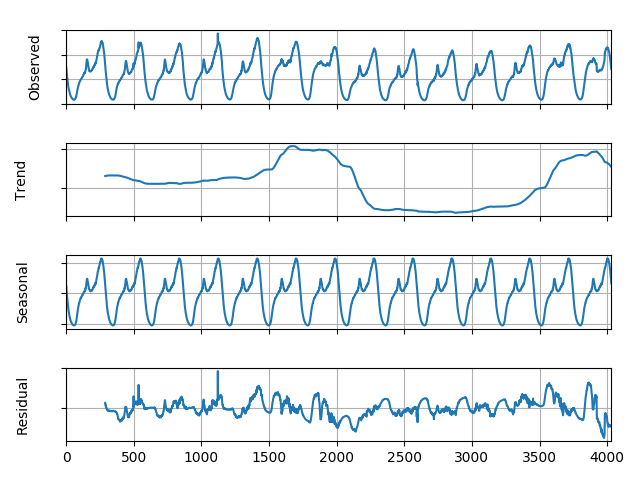
Observed 是我们现在的数据。
Seasonal 是分解出来的季节分量,可以看到分解出来的数据,与我们之前描述的数据相当相似。
Trend 就是趋势分量了,看到高峰是我们的周末,低峰是平时。我们针对这一项数据进行后续数据的预测。
Residual 是季节的余量。通过余量的范围来制定我们数据的区间范围。
3. 通过 acf,pacf 确认我们的 ARIMA 模型
我们的数据刚开始并不是若平稳的,需要将数据变成平稳的,那么就需要做差分。我的数据做了二次差分之后,变得平稳。
import matplotlib.pyplot as plt
import statsmodels.api as sm
diff1 = trend.diff()
diff2 = diff1.diff()
diff2 = diff2.dropna() # 做了差分后,之前的数据会变成 na。需要 drop 掉才能画图
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(diff2, lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(diff2, lags=40, ax=ax2)
plt.show()
确认模型为 (7, 2, 3)
图这里就不展示了。
4. 针对余项确认置信区间
d = residual.describe()
delta = d['75%'] - d['25%'] # 置信区间
low_error = d['25%'] - 1 * delta
high_error = d['75%'] + 1 * delta
5. 按照这个数据来画图
model = ARIMA(trend.dropna(), (7, 2, 3)).fit(disp=-1, method='css')
new_data = model.forecast(288)[0] # 预测之后 288 个点(一天的数据)
season_data = decomposition.seasonal
values = []
low_conf_values = []
high_conf_values = []
for i , trend_part in enumerate(new_data):
season_part = season_data[season_data.index % 288 == i].mean()
predict = trend_part + season_part
low_bound = trend_part + season_part + low_error
high_bound = trend_part + season_part + high_error
values.append(predict)
low_conf_values.append(low_bound)
high_conf_values.append(high_bound)
plt.plot(values, color='green')
plt.plot(low_conf_values, color='red')
plt.plot(high_conf_values, color='blue')
plt.plot(real_values, color='pink')
plt.show()
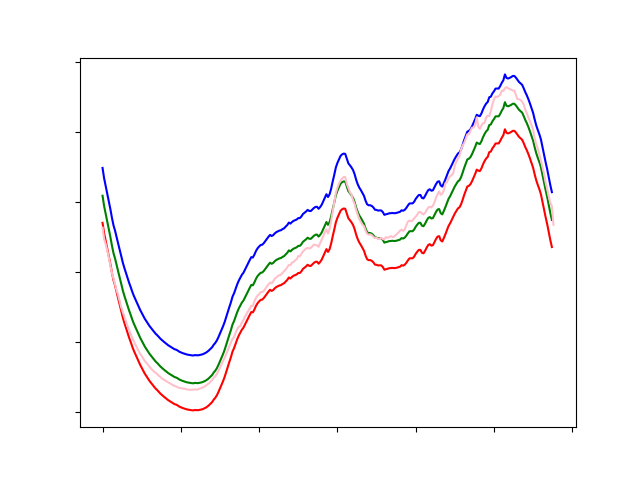
可以看到还是挺靠谱的。 最后通过计算均方根误差,得到误差大约 5 %。还是可以的。
目前对时序数据分析概念也不是很深,基本都是参考网上前人的经验在做,很多地方多不会,原理也不是很清楚,这篇文章就当一个试水,之后会带来技术向,讲原理,提升感受的文章。
参考: 用Python预测「周期性时间序列」的正确姿势 基本都是按照这篇博文来做的。